
Datatypes are Boxed-and-Tagged Values
Recall that Haskell allows you to create brand new data types like this one from lecture 1.
> data Shape = Rectangle Double Double
> | Polygon [(Double, Double)]What is the type of Rectangle ?
ShapeDoubleDouble -> Double -> Shape(Double, Double) -> Shape[(Double, Double)] -> ShapeValues of this type are either two doubles tagged with Rectangle
ghci> :type (Rectangle 4.5 1.2)
(Rectangle 4.5 1.2) :: Shapeor a list of pairs of Double values tagged with Polygon
ghci> :type (Polygon [(1, 1), (2, 2), (3, 3)])
(Polygon [(1, 1), (2, 2), (3, 3)]) :: ShapeOne can think of these values as being inside special “boxes” with the appropriate tags.
Datatypes are Boxed-and-Tagged Values
However, Haskell (and other functional languages), allow you to define datatypes recursively much like functions can be defined recursively. For example, consider the type
> data IntList = IEmpty
> | IOneAndMore Int IntList
> deriving (Show)(Ignore the bit about deriving for now.) What does a value of type IntList look like? As before, you can only obtain them through the constructors. Here, we have the constructor IEmpty takes no arguments and returns an IntList, that is
ghci> :type IEmpty
IEmpty :: IntListNow, that we have at least one value of type IntList we can make more by using the other constructor
> is1 = IOneAndMore 1 IEmpty
> is2 = IOneAndMore 2 is1
> is3 = IOneAndMore 3 is2and so on. Suppose we ask Haskell to show us is3 we get
ghci> is3
IOneAndMore 3 (IOneAndMore 2 (IOneAndMore 1 IEmpty))
ghci> :type is3
is3 :: IntListHowever, the presence of recursion does not change what the values really are, now you simply have boxes within boxes.

Recursively Nested Boxes
Of course, there is no reason why the type definition must have only one recursive occurrence of the type. You can encode general trees like
> data IntTree = ILeaf Int
> | INode IntTree IntTree
> deriving (Show)Here, each value is either a simple leaf which is a box containing an Int labeled ILeaf, such as each of
> it1 = ILeaf 1
> it2 = ILeaf 2or an internal node which is a box containing two trees, a left and right tree, and marked with a tag INode, such as each of
> itt = INode (ILeaf 1) (ILeaf 2)
> itt' = INode itt itt
> itt'' = INode itt' itt'Now, if we ask Haskell
ghci> itt'
INode (INode (ILeaf 1) (ILeaf 2)) (INode (ILeaf 1) (ILeaf 2))
ghci> :type itt''
itt' :: IntTreeNeedless to say, you can have multiple branching factors, for example you can define 2-3 trees over integer values as
> data Int23T = ILeaf0
> | INode2 Int Int23T Int23T
> | INode3 Int Int23T Int23T Int23T
> deriving (Show)An example value of type Int23T would be
> i23t = INode3 0 t t t
> where t = INode2 1 ILeaf0 ILeaf0which looks like
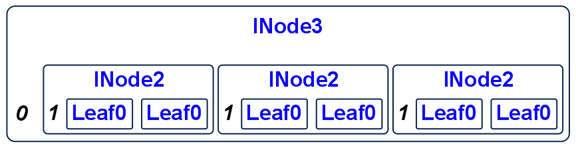
Integer 2-3 Tree
and has the type
ghci> :type i23t
i23t :: Int23TWe could go on and define versions of IntList that stored, say, Char and Double values instead.
> data CharList = CEmpty
> | COneAndMore Char CharList
> deriving (Show)
>
> data DoubleList = DEmpty
> | DOneAndMore Char CharList
> deriving (Show)and we could go on and on and do the same for trees and 2-3 trees and so on. But that would be truly lame, because we would (mostly) repeating ourselves. This looks like a job for abstraction!
The song remains the same: as when finding abstract computation patterns, we can find abstract data patterns by identifying the bits that are different and turning them into parameters. Here, the bit that is different is the underlying base data stored in each box of the structure. So, we will turn that base datatype into a type parameter that is passed as input to the type constructor.
> data List a = Empty
> | OneAndMore a (List a)
> deriving (Show)Now, as before, we may define each of the types as simply instances of the above parameterized type
type IntList = List Int
type CharList = List Char
type DoubleList = List DoubleSimilarly, it is instructive to look at the types of the constructors
ghci> :type Empty
List aThat is, the Empty tag is a value of any kind of list, and
ghci> :type OneAndMore
a -> List a -> List aThat is, the constructor two arguments: of type a and List a and returns a value of type List a. Here’s how you might construct values of type List Int (note that you can use the binary constructor function in infix form)
> l1 = OneAndMore 'a' `OneAndMore` Empty
> l2 = OneAndMore 'b' `OneAndMore` l1
> l3 = OneAndMore 'c' `OneAndMore` l2Of course, this is pretty much how the “built-in” lists are defined in Haskell, except that Empty is called [] and OneAndMore is called :.
One can use parameterized types to generalize the definition of the other data structures that we saw. For example, trees
> data Tree a = Leaf a
> | Node (Tree a) (Tree a)
> deriving (Show)and 2-3 trees
> data Tree23 a = Leaf0
> | Node2 (Tree23 a) (Tree23 a)
> | Node3 (Tree23 a) (Tree23 a) (Tree23 a)
> deriving (Show)The Tree a corresponds to trees of values of type a. If a is the type parameter, then what is Tree ? A function that takes a type a as input and returns a type Tree a as output! But wait, if List is a “function” then what is its type? A kind is the “type” of a type.
ghci> :kind Int
Int :: *
ghci> :kind Char
Char :: *
ghci> :kind Bool
Bool :: *Thus, List is a function from any “type” to any other “type, and so
ghci> :kind List
List :: * -> *What is the kind of ->? That, is what does GHCi say if we type
ghci> :kind (->)** -> ** -> * -> *We will not dwell too much on this now. As you might imagine, they allow for all sorts of abstractions over how to construct data. See this for more information about kinds.
We have (and will continue) to see that trees are crucial pillar upon which many data structures are built in Haskell. The workhorse, lists, are infact a kind of tree with exactly one child. Lets write some functions over trees.
First, here is a function that computes the height of a tree.
height :: Tree a -> Int
height (Leaf _) = 0
height (Node l r) = 1 + max (height l) (height l)The readability of the above, makes an English description redundant! Good old recursion. You have a base case for the Leaf pattern (namely 0) and a recursive or inductive case for the Node pattern (namely the larger of the recursively computed heights of the left and right subtrees.) Lets give it a whirl
> st1 = Node (Leaf "cat") (Leaf "doggerel")
> st2 = Node (Leaf "piglet") (Leaf "hippopotamus")
> st3 = Node st1 st2ghci> height st1
1
ghci> height st3
2How do we compute the number of leaf elements in the tree?
size :: Tree a -> Int
size (Leaf _) = 1
size (Node l r) = (size l) + (size l)How about a function that gathers all the elements that occur as leaves of the tree:
toList :: Tree a -> [a]
toList (Leaf x) = [x]
toList (Node l r) = (toList l) ++ (toList r)Did you spot the pattern? What are the different bits? The base value and the operation? So we can write a tree folding routine as
treeFold op b (Leaf x) = b
treeFold op b (Node l r) = (treeFold op b l) `op` (treeFold op b r)Does that work? Well, we can easily check that
What does treeFold (+) 1 t return?
0What does treeFold max 0 t return?
0But what about toList ? Urgh. Does. Not. Work. We painted ourselves into a corner. For size and height the base value is a constant, but for toList the base value depends on the actual datum at the leaf! Thus, we need two operations: one to combine the results of the left and right subtrees, and another to give us the value at a leaf. In other words, the base b needs to be a function that takes as input the leaf value and returns as output the result of folding over the leaf.
> treeFold op b (Leaf x) = b x
> treeFold op b (Node l r) = (treeFold op b l)
> `op`
> (treeFold op b r)Now we can write the size as
> size = treeFold (+) (const 1)How would you write height ?
> height = treeFold undefined undefinedwhere const 0 and const 1 are the respective base functions that ignore the leaf value and just always return 0 and 1 respectively.
Can you guess the definition of const ?
Which of the following implements toList :: Tree a -> [a]
toList = treeFold (:) []toList = treeFold (++) []toList = treeFold (:) (\x -> [x])toList = treeFold (++) (\x -> [x])What about the equivalent of map for Trees ? We could write the recursive definition
treeMap :: (a -> b) -> Tree a -> Tree b
treeMap f (Leaf x) = Leaf (f x)
treeMap f (Node l r) = Node (treeMap f l) (treeMap f r)but recursion is HARD TO READ do we really have to use it ?
DO IN CLASS
Sweet! see how we just used the constructors as functions! Lets take it out for a spin.
ghci> st1
Node (Leaf "cat") (Leaf "doggerel")
ghci> treeMap length st1
Node (Leaf 3) (Leaf 8)
ghci> st2
Node (Leaf "piglet") (Leaf "hippopotamus")
ghci> treeMap reverse st2
Node (Leaf "telgip") (Leaf "sumatopoppih")It was all well and good to see the patterns in tiny “toy” functions. Needless to say, these patterns appear regularly in “real” code, if only you know to look for them. Next, we will develop a small library that “swizzles” text files.
We will start with a beginner’s version that is riddled with explicit recursion.
Next, we will try to spot the patterns and eliminate recursion using higher-order functions.
Finally, we will parameterize the code so that we can both “swizzle” and “unswizzle” without duplicate code.
Needless to say, the code can be cleaned up even more, and I encourage you to do so. For example, rewrite the code that swizzles Char so that instead of using association lists, it uses the more efficient Map k v (maps from keys k to values v) type in the standard library module Data.Map.
> main :: IO ()
> main = return ()